
Таблица расчета петель.: ru_knitting — LiveJournal
?- Рукоделие
- Cancel
- Mood: creative
Наверное не найдется вязальщицы, которой бы нравилось выполнять пробный набор петель.
Однако, если вы хотите связать изделия по размеру, то эта операция неизбежна.
Пробный набор петель должен обязательно выполняться на тех же спицах и той же пряжей, что и будущее изделие. Обычно набирают 30 петель и вяжут образец длиной 10 см, затем петли необходимо закрыть.
Пробный образец не должен быть слишком маленьким, так как в этом случае будет сложнее произвести расчеты.
Перед тем как произвести замер образец надо растянуть и намочить, а после — высушить. Сантиметром для замера обычно не пользуются, лучше всего счетную рамку или треугольник прижать к поверхности образца и таким образом измерить. Чтобы минимизировать допуск неточности мерять необходимо от середины.
Таким образом, вы должны посчитать ряды и петли в квадрате 5X 5 см. Полупетли необходимо считать тоже, так как при пересчете на целое изделие эта цифра может оказаться значительной. Чтобы посчитать ряды пользуйтесь изнаночной стороной, так как с этой стороны считать ряды легче. Ну и соответственно ряды считаются по высоте, а петли по ширине, а затем полученные цифры сравниваются с данными в таблице, которая указана ниже. Все цифры даются в пересчете на 10 см. Если вдруг полученные данные не совпали с данными в таблице, то значит, необходимо поменять спицы. Если петель и рядов получилось больше, то необходимо поменять ваши спицы на более тонкие и наоборот.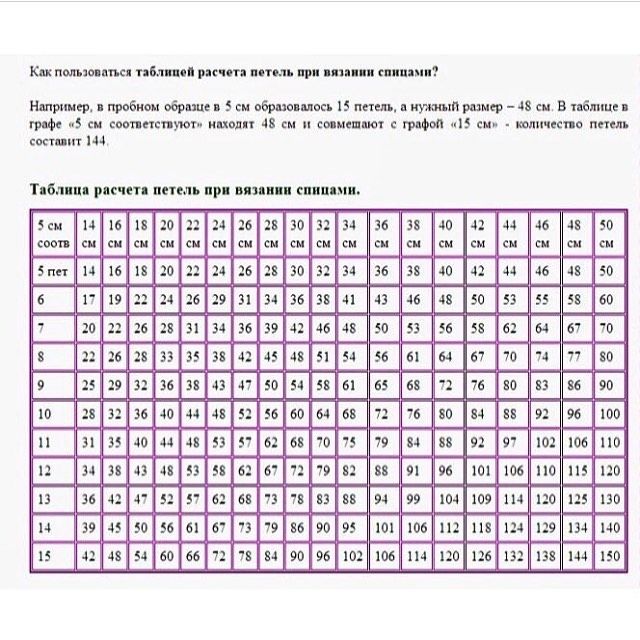
Как пользоваться таблицей?
Например, в пробном образце в 5 см образовалось 15 петель, а нужный размер – 48 см. В таблице в графе «5 см соответствуют» находят 48 см и совмещают с графой «15 см» — количество петель составит 144.
Взято www.liveinternet.ru/community/3203889/po
Tags: расчет плотности и количества пряжи, техники
Subscribe
почему же ты не верил, что зиме придёт конец? (c)
внеочередная болталка скоро и лето! готовимся. но не забываем о том, что возможны ещё холода… 1. 2. 3. 4. 5. 6. 7. 8.…
Три юбки Норо
Я люблю носить юбки и платья! В моем ежедневном гардеробе десятка два самых разных юбок, плюс ещё несколько в нарядном отделе. Они в основном из…
Апрельский флешмоб
За март месяц было опубликовано 25 постов с многочисленными жилетами. Благодарим всех, кто откликнулся и принял участие, большое спасибо! Апрель…
Photo
Hint http://pics. livejournal.com/igrick/pic/000r1edq
livejournal.com/igrick/pic/000r1edq
Расчет петель и рядов Прежде чем начать вязание изделия, необходимо построить чертеж выкройки в натуральную величину к каждой детали выбранной модели. Затем сделать расчет петель для набора начального ряда, исходя из плотности связанного образца и размера выкройки. Определить плотность вязания рисунка по ранее связанному образцу нитками и спицами, которыми будут выполняться детали. Для большей точности расчета при выполнении образца набрать максимальное количество петель. Например, для образца набрать 51 петлю и провязать 8 см. Петли последнего ряда обязательно закрепить, только тогда обработать образец в соответствии с фактурой: увлажнить или постирать, прогладить, растянуть. После отделочных работ измерить связанный образец по горизонтали и вертикали. По горизонтали образец равен 17 см, тогда 51 п.: 17=3 п. Следовательно, плотность вязания по ширине составляет: 3 петли в 1 см. Зная расчет петель на 1 см, легко рассчитать количество петель для набора начального ряда каждой детали. Пример. Ширина спинки по линии низа равна 50 см, плотность— 3 петли в 1 см: 3 п. X 50 = = 150 п. Значит, 150 петель — рассчитанное количество петель для набора начального ряда. Точность расчета можно проверить накладыванием связанного образца на сантиметровую ленту. При накладывании образца на выкройку детали необходимо делать расчет за вычетом двух кромочных петель. В нашем варианте связанный образец, равный 51 петле, укладывается по ширине в 50 см 3 раза (оставшиеся 4 петли в счет набора не входят): 3 п. X 51 = 153 п. Если в рассчитанное количество петель для набора не укладывается ритм выбранного рисунка вязки, следует прибавить или уменьшить количество петель, ориентируясь структурой рисунка. Плотность вязания каждой исполнительницы различна, поэтому при работе могут быть отклонения против рассчитанного числа. Расчет количества рядов по плотности вязания по высоте делается в том случае, если необходимо расширить или заузить провязываемое полотно по линии реглана, или выполнить плечевой скос, или рукава, оформить вытачки и др. По связанному образцу определить плотность вязания по высоте на 1 см. Связанный образец из 40 рядов равен 8 см по высоте, тогда на 1 см приходится: 40 р. : 8=5 р. Следовательно, плотность вязания по высоте в 1 см равна 5 рядам. Общее количество рядов провязанного полотна высотой в 30 см будет равно: 5 р.х30=150 р. Предлагаю ознакомиться с мастер-классом Людмилы Арюткиной, опубликованном на Осинке.ру
К оглавлению | Меню сайта Форма входа Поделись Статистика Онлайн всего: 1 Гостей: 1 Пользователей: 0 |

 В этом случае можно сделать перерасчет петель по плотности уже связанной детали,
В этом случае можно сделать перерасчет петель по плотности уже связанной детали,Использование цикла for в расчетах в EDC/CDMS
Все категорииCDMSeConsentSMS
Все категорииCDMSeConsentSMS
- CDMS
Руководство по CDMS Castor Руководство по расчетам Castor CDMS Часто задаваемые вопросы Статьи для менеджеров данных Документы по выпуску соответствия стандартам Castor CDMS
- электронное согласие
- SMS
Кастор СМС инструкция Документы о соответствии стандартам Castor SMS
- Кастор Коннект
Документы о соответствии стандартам Castor Connect
- Служба поддержки
Новости Другие источники
- Страница статуса
+ Еще
Содержание
Синтаксис цикла for Пример цикла
Иногда при вычислениях необходимо повторить определенное действие несколько раз.
Проще говоря, цикл for — это повторение переменных, опций или всего, что у вас есть. Это выполняется в виде цикла, поэтому он будет проходить через каждый определенный экземпляр, пока не будет выполнено условие для завершения цикла. Это означает, что вам нужно будет определить, где начинается цикл for, где он заканчивается и как выполняется итерация (будь то на всех определенных экземплярах).
Синтаксис цикла for
for ( инициализация ; состояние ; конечное выражение ) {
блок кода для выполнения
} - Инициализация: обычно устанавливает начальный счетчик
- Условие: цикл будет выполняться, пока выполняется это условие, если условие не выполняется, цикл останавливается
- Final-expression: счетчик, показывающий, выполняются ли итерации для всех экземпляров
- Выполняемый блок кода: этот код будет выполняться каждый раз при выполнении итерации
Вы часто будете видеть что-то подобное в операторе цикла:
for (i = 0; i<10; i+1) {
. ..
}
..
}  ..
}
..
} Это означает, что цикл начинается с 0 (первый экземпляр), заканчивается после 10 итераций и увеличивается на 1 (таким образом, итерации выполняются для всех экземпляров без пропусков). Они могут быть определены по-разному, в зависимости от того, что вам нужно сделать. Это «i» здесь полезно, потому что его можно использовать дальше в цикле, чтобы найти номер итерации, как в примере ниже.
Оператор в скобках устанавливает условия для цикла, но фактическое вычисление (то, что мы хотим, чтобы программа делала) будет в блоке кода. Фактический расчет определяется как любой другой и может также содержать операторы if/else.
Пример цикла For
Давайте проясним это на примере. Вот пример того, как рассчитать общую оценку нескольких переменных, оставив некоторые из них пустыми.
'##allowempty##';
переменные var = [{переменная_1}, {переменная_2}, {переменная_3}];
общая сумма = 0;
for (i=0; i < variable.length; i++) {
значение переменной = переменные[i];
если (значение != 'Н/П') {
итог = итог + стоимость;
}
};
общий;
Давайте посмотрим, что означает этот код, начиная с первых трех строк:
'##allowempty##';
переменные var = [{переменная_1}, {переменная_2}, {переменная_3}];
общая сумма = 0; - Это позволяет учитывать при расчете пустые поля, т. е. незаполненные поля.
- Эта строка создает список интересующих вас переменных. Замените имена в скобках своими именами переменных. Этот список будет использоваться в цикле for.
- Создана переменная, которая будет использоваться для хранения общей оценки.
 е. незаполненные поля.
е. незаполненные поля.
В следующих 6 строках мы создаем цикл for:
for (i=0; i < variable.length; i++) {
значение переменной = переменные[i];
если (значение != 'Н/П') {
итог = итог + стоимость;
}
}; - Запущен цикл for. Создается счетчик «i», который начинается с 0. Цикл завершается, когда i становится равным длине списка «переменных», определенного выше. В нашем случае цикл заканчивается при i = 3, потому что в списке 3 переменные. После каждого цикла i увеличивается на 1 (i++).
- Создана переменная 'значение'. Он находит каждую переменную в списке, поэтому, когда i = 0 (первая итерация цикла), первая переменная в списке будет найдена и сохранена в «значении».
- Оператор if проверяет, не является ли значение пустым ('NA'). Если это так, значение добавляется к общему баллу.
 Если это так, значение добавляется к общему баллу.
Если это так, значение добавляется к общему баллу.
Наконец, возвращается общий балл:
всего;
Когда вы заполните данные, вы увидите, что общий балл будет показан в поле расчета. Если все переменные оставить пустыми, общий результат будет равен 0, потому что это то, что мы определили в начале.
Дополнительную информацию о циклах for можно найти здесь: JavaScript For Loop
Была ли эта статья полезной?
Да
Нет
Оставить отзыв об этой статьеpython - Как написать цикл для вычисления среднего значения для повторяющихся сущностей
У меня возникла проблема с python при построении цикла (или вложенного цикла) для моего расчета. У меня очень большой набор данных (около 600 тыс. записей) с повторяющимися идентификаторами и их значениями. Я хотел бы сформировать цикл, который начинается с первой записи, смотрит, повторяется ли он и сколько раз он это делает, и вычисляет среднее значение для одного и того же идентификатора.
У меня очень большой набор данных (около 600 тыс. записей) с повторяющимися идентификаторами и их значениями. Я хотел бы сформировать цикл, который начинается с первой записи, смотрит, повторяется ли он и сколько раз он это делает, и вычисляет среднее значение для одного и того же идентификатора.
Например, в приведенной ниже таблице я хотел бы, чтобы она возвращала среднее значение a = 2, среднее значение b = 4 и среднее значение c = 1.
Я попробовал вложенный цикл for, приведенный ниже, но полностью потерял след.
| ID | Значение |
|---|---|
| и | 1 |
| и | 3 |
| б | 3 |
| б | 4 |
| б | 5 |
| с | 1 |
для i в диапазоне (0, len (ID)):
if ID[i] == ID[i+1]: #если следующий ID равен текущему
for j in range (i,len(ID)): #ищите, сколько повторяющихся значений для текущего ID
если ID[j] != ID[j+1]:
я=j
перерыв
#так как известно, сколько существует повторяющихся идентификаторов, каким-то образом усреднить их и продолжить для второго (отличного) идентификатора
- питон
- петли
12
Это фрагмент кода, в котором не используются никакие внешние модули.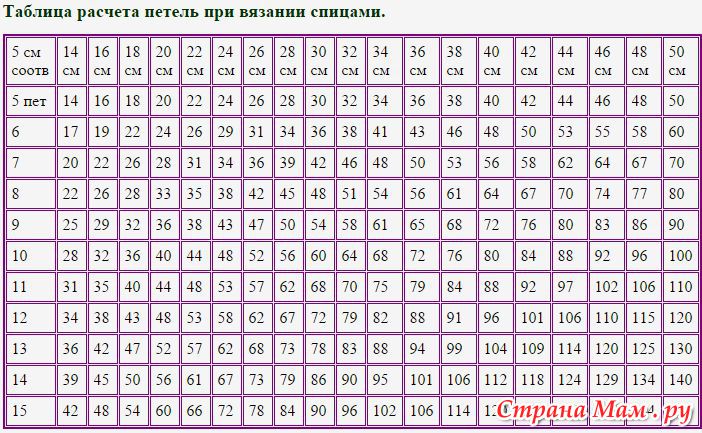 Вы можете использовать их, если хотите, но решили оставить это, так как это все еще вариант.
Вы можете использовать их, если хотите, но решили оставить это, так как это все еще вариант.
по умолч.сред.(сл):
возвращаемая сумма (lst) / len (lst)
имя_файла = "mycsvfile.csv"
средние значения = дикт ()
все_значения = дикт()
с открытым (имя файла, "r") как f:
# прочитать все строки и сохранить
для строки в f.readlines():
split = line.split(",") # разделить запятую
row_id = разделить[0]
пытаться:
# "ID находится в первом столбце. Значение находится в пятом." -ОП
значение = поплавок (разделить [4])
# проверяем есть новый ID или нет
если row_id в all_values.keys():
all_values[row_id].append(значение)
еще:
all_values[row_id] = [значение]
кроме ValueError:
pass # игнорировать строки заголовка
# получить средние значения в словаре
для k, v в all_values.items():
средние [k] = средние (v)
# распечатать данные, чтобы показать, что они верны
для k, v в mediums. items():
распечатать (f"{k}: {v}")
 items():
распечатать (f"{k}: {v}")
items():
распечатать (f"{k}: {v}")
Этот фрагмент кода считывает все данные из файла CSV, а затем заносит средние значения в словарь. Ключ — это идентификатор, значение — это среднее значение.
Как это работает: Этот код создает 2 словаря:
# all_values:
{ID: [list_all_values_here]}
# например
{'б': [3, 4, 5]}
#####
# средние значения:
{ID: средний}
# например
{'б': 3}
Это начинается со считывания всех данных из файла CSV и помещения их в соответствующий словарь all_values. После чтения всех данных мы перебираем все пары ключ: значение в словаре all_values и получаем среднее значение списка, содержащего все значения.
Мы перебираем все пары ключ:значение здесь, в этих двух строках, и добавляем среднее значение в словарь средних значений.
для k, v в all_values.items():
средние [k] = средние (v)
Затем мы распечатываем все значения в конце, чтобы показать, что они верны.
0
Если вам просто нужен алгоритм:
Так как данные отсортированы, можно итерировать внешний цикл по идентификаторам, сохраняя при этом две переменные — одна будет подсчитывать количество одинаковых идентификаторов, а другая — суммировать значения. Когда вы дойдете до итерации, где будет найден новый идентификатор, это ваш сигнал для вычисления среднего (сумма значений, деленная на количество идентификаторов), распечатайте его, а затем повторите то же самое снова и снова для следующих идентификаторов.
Когда вы дойдете до итерации, где будет найден новый идентификатор, это ваш сигнал для вычисления среднего (сумма значений, деленная на количество идентификаторов), распечатайте его, а затем повторите то же самое снова и снова для следующих идентификаторов.
Вы можете сделать что-то вроде этого - перебирать идентификаторы и значения, сравнивая текущий идентификатор с предыдущим идентификатором, а когда он отличается, вычисляя и сохраняя среднее значение.
ID = ["а", "а", "б", "б", "б", "в"]
значения = [1,3,3,4,5,1]
средние = {}
предыдущий_id = нет
количество = нет
всего = нет
для id_, значение в zip(ID, значения):
если id_ == предыдущий_id:
количество += 1
итог += стоимость
еще:
если предыдущий_ид не равен None:
средние значения[previous_id] = всего / количество
количество = 1
итог = стоимость
предыдущий_id = id_
Averages[id_] = total / count # чтобы не пропустить последний ID
Но будет намного лучше и быстрее использовать pandas :
импортировать pandas как pd df = pd.
